I Finally Passed the dbt Analytics Engineering Certification. Here's What It Took.
Five years with dbt. Two near-misses. One pretest. A much deeper respect for Jinja.
dbt Analytics Engineering Certification · Issued to Logan Banks · April 23rd, 2026
The short version
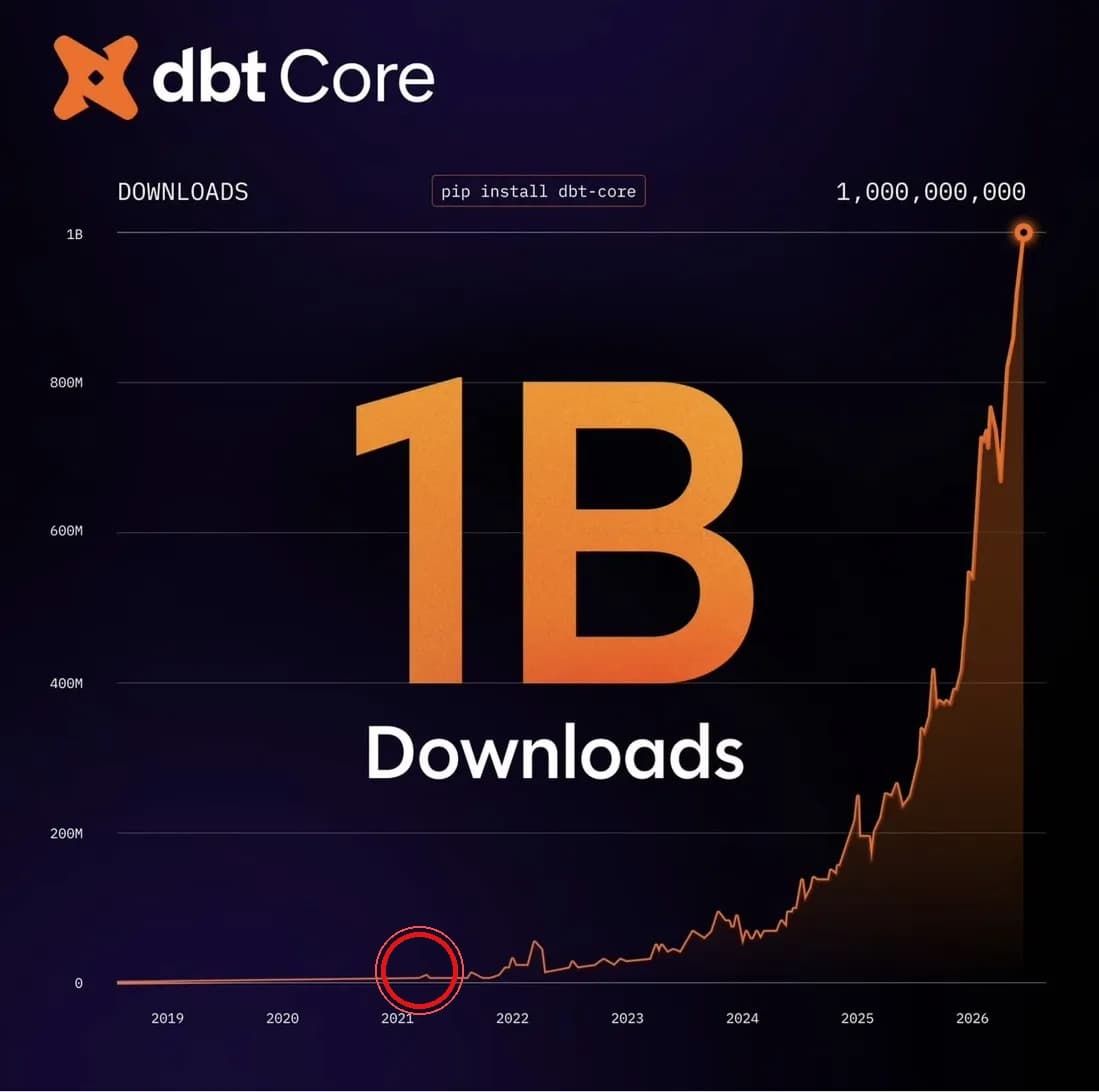
I passed the dbt Analytics Engineering Certification. I have been building with dbt since early 2021 (that small bump on the chart where I started is circled below, right before the line went vertical), I failed by a few points in 2023, failed again by a few points in 2024, and finally closed the gap in 2026. Along the way I picked up a much deeper respect for JSON parsing, Jinja templating, and how precisely dbt Labs wants you to remember every config key.
If your company is looking to stand up a dbt instance and wants a certified analytics engineer driving it, that is exactly what MHNG does. I would love to talk.
Why this matters now
dbt Labs just crossed 1 billion downloads. That is not a vanity number. It is the shape of the analytics engineering discipline itself. dbt's 2026 State of Analytics Engineering Report, surveying 363 practitioners and leaders, tells a story every data leader should be paying attention to:
- Trust in data jumped from 66% to 83% year over year as the top organizational priority, the steepest single-year increase of any measured objective.
- Speed of shipping data products climbed from 50% to 71%.
- 72% of teams now prioritize AI-assisted coding, but only 24% prioritize AI-assisted pipeline management (testing, observability, quality).
- 71% cite incorrect or hallucinated outputs reaching stakeholders as a top concern.
- 57% report increased warehouse and compute spend, while only 36% report increased team budgets.
The headline: AI is making code fast to produce and governance harder to keep up with. Trust has become the bottleneck, and trust lives in transformation, testing, and documentation. That is dbt's home turf. It is also, not coincidentally, why I keep investing in it.
Why I kept coming back to this exam
I have been using dbt in production since early 2021. In that time I have built out the analytics platform at Pumpkin Pet Insurance, contributed to the stack at Dispatch, and now run MHNG, where dbt is the transformation backbone of everything we ship. I have written, by my count, well over 2,000 dbt models across my career, with thousands of tests backing them: generic and singular, unit tests, source freshness, contract enforcement, and a lot of custom Jinja assertions wrapped around real production data flows.
So why bother with a certification after five years and two companies? A few reasons:
- Signal. Experience is the meat. The certification is the seasoning. Buyers want both.
- Completeness. The exam forces you into corners of dbt you may have worked around your whole career. I learned things my real job had let me skip.
- Stubbornness. I had failed it twice already. Leaving that on the board did not sit right with me.
Attempt 1 (2023) and Attempt 2 (2024): what went wrong
Both attempts, I missed by a handful of points. Looking back, the gap was never conceptual. I could build, debug, and deploy dbt projects at a senior level. The gap was in the fine print.
The exam wants you to know, for example:
- The exact precedence of
varsresolution acrossdbt_project.yml, CLI flags, and environment variables. - The difference between
dbt clone,dbt retry, and state selectors likestate:modified+. - What happens when you combine
--select,--exclude,--selector, and--deferat the same time. - The precise behavior of
on_schema_changefor each value:ignore,append_new_columns,sync_all_columns,fail.
In both 2023 and 2024 I walked out knowing I had lost points on nitpicky configuration specifics rather than any real dbt capability. Which is useful feedback, but painful at $200 per attempt.
What I did differently this time
I stopped studying like someone who already knew the tool and started studying like someone who had never seen it.
Step 1: I had AI build me a pretest
Instead of rereading the study guide from the top, I had Claude generate a full pretest spanning every domain and subdomain in dbt's V.9.0 official study guide. The eight domains are:
- Developing dbt models
- Model governance (contracts, versions, access)
- Debugging data modeling errors
- Managing data pipelines
- Implementing dbt tests
- Creating and maintaining documentation
- Implementing external dependencies (exposures, source freshness)
- Leveraging dbt state (retry, clone, state selectors)
The pretest gave me a score per subdomain. That became my study map. I knew, within an hour, exactly what I needed to spend my time on.
Step 2: I drilled the weak spots, not the strong ones
My weak spots were concentrated around governance features that I had not personally implemented at scale (model contracts, model versions, model access modifiers, group assignments) and state management in CI (the exact state:modified+ semantics, defer versus favor-state, when dbt clone copies versus when it creates a pointer).
I built a small project to exercise every one of those features. Not a portfolio project. A sparring partner.
Step 3: I leaned on the guides from people who had walked the path
These writeups were the ones that made a real difference, in order of usefulness for me:
- Aimpoint Digital's full guide (link). By far the most thorough walkthrough of what the exam actually tests and how scoring works with unscored research questions. Thanks to the Aimpoint Digital team for putting this together.
- Daan Vandenreyt's “Zero to dbt Certified in 4 Weeks” at Biztory (link). Great phased approach and checklist.
- Eunice Wadjom's “How I Passed” on Medium (link). The 4-step roadmap (study guide, build project, Qanalabs, Udemy timed mocks) is the cleanest framework I have seen.
- Rajeev Rajaram's preparation tips (link). Specific topics that showed up on the v1.7+ exam.
- Qanalabs free practice tests (link). The closest feel to the real question style.
- dbt Learn free courses (link). The official fundamentals, advanced deployment, and testing paths are worth working through even if you have done the work in production.
- Brian Shand's “dbt Analytics Engineering Certification - Practice Exams” on Udemy (link). Well-structured timed practice exams that surfaced the exact config-nitpick categories I kept losing points on (LinkedIn). Worth every dollar.
- Rahul Prasad's “dbt Analytics Engineering Certification Practice Tests” on Udemy (link). Rahul is Head of Analytics at Datatonic and a Google Champion Innovator (LinkedIn). His tests lean into state management and governance edge cases in a way that complements Brian's set really well. Running both back-to-back was most of my Jinja rigor.
If any of the authors above happen to read this, thank you. You saved me real time.
Step 4: When the exam showed me material I had never seen, I fell back on five years of muscle memory
Even after all the prep, the exam still surfaced a handful of questions where the answer was not cleanly spelled out in any study material I had read. That is where the 2,000+ models, the thousands of test runs, the 3 AM incremental model debugging sessions, and the “why is my snapshot missing rows” postmortems actually earned their keep. You cannot fake the fingertip feel for dbt. You have to have built with it.
A deep dive on JSON inside dbt
JSON is one of those topics where dbt sits in the middle of a conversation between the adapter, the warehouse, and the templating engine, and most teams never step back to understand the full picture.
Where JSON shows up in dbt
In your sources. Nearly every modern ingestion tool (Fivetran, Airbyte, Stitch, dlt, and yes, my own Rust extraction layer at MHNG) lands data in a semi-structured form. Append-only ingestion tables with a _airbyte_data JSON column, HubSpot records with nested properties objects, Stripe events with deeply nested data.object trees. You will almost certainly be unnesting JSON somewhere in your staging layer.
In the compiled output. Every dbt run produces a manifest.json, a run_results.json, a catalog.json, and a sources.json inside target/. These are the “dbt metadata graph.” Every downstream piece of tooling (dbt Explorer, dbt Cloud, dbt Mesh, third-party observability, AI copilots) reads from these JSON artifacts. If you understand what is in manifest.json, you understand how dbt actually sees your project.
In configuration.dbt's configuration is YAML, but under the hood dbt parses every YAML file into a Python dict, which is then JSON-serialized into the manifest. The moment you understand that pipeline, a lot of “why is my config not taking effect” mysteries dissolve.
YAML to JSON parsing: the hidden layer underneath every dbt config
Every dbt_project.yml, schema.yml, sources.yml, selectors.yml, profiles.yml, and packages.yml goes through the same rough pipeline:
- Read the YAML file from disk.
- Parse it with a YAML loader (PyYAML or ruamel.yaml, depending on the code path) into Python native types:
dict,list,str,int,float,bool,None. - Validateit against a Pydantic-style schema (dbt's contracts internal).
- Mergeit with other YAML blocks and project defaults following dbt's precedence rules.
- Serialize the final resolved state into
manifest.jsonas JSON.
JSON is the lowest common denominator in this pipeline. YAML 1.2 is technically a superset of JSON (any valid JSON is valid YAML), but the reverse is not true. That asymmetry is where bugs live.
Here is a concrete example of the round trip. This schema.yml block:
models:
- name: stg_customers
description: "Customer records from production"
config:
materialized: table
tags: [pii, customer_domain]
columns:
- name: customer_id
data_type: varchar
tests:
- unique
- not_nullParses into this Python dict, which is what dbt actually operates on:
{
"models": [
{
"name": "stg_customers",
"description": "Customer records from production",
"config": {
"materialized": "table",
"tags": ["pii", "customer_domain"]
},
"columns": [
{
"name": "customer_id",
"data_type": "varchar",
"tests": ["unique", "not_null"]
}
]
}
]
}And that dict eventually lands inside target/manifest.json at nodes["model.my_project.stg_customers"] as nested JSON. Once it is there, every downstream tool (dbt Explorer, Elementary, Datafold, your custom AI copilot) reads it the same way.
The YAML gotchas that quietly break dbt projects
The most painful YAML-to-JSON parsing bugs in dbt come from YAML 1.1 quirks that do not exist in JSON:
- The Norway problem. In YAML 1.1,
no,No,NO,false,off, andnall parse as booleanfalse. If your source is namedno(yes, real story with a client in Norway), the stringnobecomes the booleanFalseand your source lookup breaks. Always quote string values that could be interpreted as booleans. - Numeric strings. Zip codes, account numbers, version strings.
09in unquoted YAML is a parse error on strict parsers and an octal number on others.1.10becomes the float1.1, dropping the trailing zero. Always quote. - Booleans that look like strings.
on,yes,trueall parse as booleans. If yourmetatag value is meant to be the string"on", quote it. - Multi-line strings. The difference between
|,>,|-, and>-changes whether newlines are preserved and whether trailing whitespace is stripped. This matters a lot when you are shoving SQL into ametafield. - Anchors and aliases. YAML supports
&anchorand*aliasfor reuse. dbt mostly handles these, but some tools that read YAML-as-text-then-convert-to-JSON will silently drop anchored references. If your config refactor “suddenly stops working” after a tooling upgrade, check your anchors.
These are not abstract. I have debugged every one of these at least once, and a few of them twice.
Why this matters for dbt Mesh, dbt Agents, and AI copilots
dbt Mesh cross-project refs, dbt's emerging AI Agents, and any custom copilot you build on top of your project all consume the JSON representation, not the YAML. Your YAML is the author interface. The JSON manifest is the machine interface. If you want to:
- Generate dbt docs programmatically
- Auto-build ERDs from your models (which is exactly what I do with MHNG's key registry, populated from
metatags) - Pipe dbt metadata into an LLM context window
- Validate contract compliance in CI
All of that work happens against the JSON output, not the YAML input. Internalizing that split is one of the higher-leverage pieces of mental model you can build as an analytics engineer.
Programmatic YAML manipulation: the pattern I use at MHNG
For MHNG's compliance-native infrastructure, I lean on a specific pattern: YAML is the source of truth that humans edit, JSON is the wire format that tools consume, and Python sits in the middle to mediate. A simplified version of the core helper looks like this:
import yaml
import json
from pathlib import Path
def schema_yml_to_json_node(schema_yml_path: Path) -> dict:
"""
Read a dbt schema.yml and return its normalized JSON representation,
suitable for registering in MHNG's key registry or feeding to an agent.
"""
with schema_yml_path.open() as f:
# safe_load rejects arbitrary Python object construction
parsed = yaml.safe_load(f)
# Pydantic-style validation would happen here in production
return json.loads(json.dumps(parsed, default=str))Two points worth flagging: always use yaml.safe_load, never yaml.load (the latter can execute arbitrary Python and is a real attack vector), and the json.loads(json.dumps(..., default=str)) pattern normalizes any non-JSON-native types (like datetime) into strings so downstream consumers never choke.
Warehouse-specific JSON: the part the exam won't test but your job will
This is not on the exam, but if you want to actually use dbt well, you need to understand how each adapter handles JSON:
- Snowflake uses the
VARIANTtype with dot-notation (payload:customer.email::string) and functions likeFLATTEN,GET_PATH,PARSE_JSON, andOBJECT_CONSTRUCT. - BigQuery uses native
JSONandSTRUCTtypes withJSON_EXTRACT_SCALAR,JSON_VALUE,UNNEST, and the newerLAX_*functions. - Databricks uses
get_json_object,from_jsonwith a schema, and VARIANT in the Unity Catalog era. - Postgres (and my daily driver Neon) uses
JSONBwith->,->>,#>,#>>, andjsonb_array_elements. - Redshift has the deeply limited
json_extract_path_text,json_extract_array_element_text, and more recentlySUPERtype.
A production-grade dbt project almost always wraps these adapter-specific patterns in a cross-database macro with adapter.dispatch. That is where JSON parsing stops being a quirk and starts being a reusable part of your transformation stack.
Why JSON literacy matters for the exam
The exam will test JSON at the config level: how source schemas are defined, how model-level configs propagate, how metatags roll up. It will not test warehouse JSON functions. But if you understand that the entire dbt project is, at runtime, a JSON graph being compiled and executed, a lot of the state management questions (“what does state:modified+actually diff against?”) suddenly make sense.
The answer, for what it is worth, is the manifest.json from your previous run compared against the one from your current compile.
A thorough examination of Jinja, and why dbt is a templating problem
If you take away one thing from this whole post, let it be this: dbt is not a SQL tool. dbt is a Jinja tool that emits SQL.
Jinja is the templating language that dbt runs on. It was created by Armin Ronacher (the Flask guy) for Python web frameworks. dbt Labs adopted it because it gave analysts something no raw SQL workflow ever could: control flow, variables, reusable macros, and dynamic dependency resolution.
What Jinja actually does in your dbt project
When you write:
select *
from {{ ref('stg_customers') }}You are not writing SQL. You are writing a Jinja template that compiles to SQL. The {{ ref('stg_customers') }} is a Jinja expression that dbt resolves at compile time. It:
- Looks up
stg_customersin the current project's manifest. - Retrieves the fully qualified
{database}.{schema}.{table}identifier. - Registers a dependency edge in the DAG.
- Substitutes the identifier into the template.
That is why you cannot run dbt SQL directly in your warehouse console without compiling it first, and why dbt compile is a first-class command.
The Jinja primitives you must internalize
Expressions are wrapped in {{ ... }}. They produce output. {{ ref('x') }}, {{ var('my_var') }}, {{ this }}, {{ target.schema }} are all expressions.
Statements are wrapped in {% ... %}. They perform logic without producing output. {% if %}, {% for %}, {% set %}, {% macro %}, {% endmacro %} are statements.
Comments are wrapped in {# ... #}. They do not render and are not visible in compiled SQL.
Filters are applied with the pipe operator: {{ my_string | upper }}, {{ my_list | length }}, {{ my_date | as_text }}.
Tests are applied with is: {% if my_var is defined %}, {% if my_var is string %}.
Whitespace control uses the minus sign: {%- if x -%} strips whitespace before and after the tag. This is where people lose exam points. Missing one dash changes your compiled output.
Why the exam hits so hard on Jinja
The exam will ask you to:
- Pick the correct macro signature from four almost-identical options.
- Identify where a missing
{% endmacro %}or{% endif %}breaks compilation. - Predict the compiled output of a for-loop with whitespace control characters.
- Choose between
var()andenv_var()for a given configuration scenario. - Distinguish
generate_schema_namefromgenerate_alias_namefromgenerate_database_namebehavior.
This is not trivia. If you do not know these, you cannot debug a real macro at 2 AM when a production job fails. The exam is right to care. I just wish it cared in slightly less punishing ways.
Where I went deeper than my day job had taken me
My biggest Jinja growth areas during prep were:
adapter.dispatchand namespace-aware macro overriding. The pattern for shipping cross-database dbt packages.- The
graphcontext variable, which gives you runtime access to the entire manifest from inside a macro. Absurdly powerful for metadata-driven modeling. run_queryversusstatementblocks, and when each executes relative to compilation.on-run-startandon-run-endhooks combined with macros that register metadata back into the warehouse. This is how I build MHNG's key registry and ERD generation pipeline.- Builtins (
builtins.ref,builtins.source) for safely extending dbt's core resolution without breaking the DAG.
None of that came from the exam. The exam was the forcing function that made me actually sit down and internalize it.
On the nit-pickiness of the exam itself
I have to be honest here. A real slice of the questions on this exam are not testing your understanding of dbt. They are testing whether you remember a very specific piece of syntax, punctuation, or directory structure. Some examples from what I lost points on across all three attempts:
- Packages path. Do installed dbt packages land in
packages/or indbt_packages/? (It isdbt_packages/. It used to bedbt_modules/in older versions of dbt, which is still the wrong answer.) - Quoting inside
packages.yml. Is the version quoted or unquoted? Is itversion: 1.0.0orversion: "1.0.0"orversion: '1.0.0'? All three look right at a glance. Only the quoted forms are actually safe, because unquoted versions like1.10get parsed as the float1.1by the YAML loader and silently drop the trailing zero. require-dbt-versionspacing. Is itrequire-dbt-version: ">=1.8.0"orrequire-dbt-version: ">= 1.8.0"? Does the space inside the double quotes matter? (Both parse, but dbt's internal version comparator is strict about the operator syntax it accepts, and the exam will happily offer you four answers where only the exact-right spacing is correct.)store_failures. Is itstore_failures: trueorstore_failures: Truein YAML? (Lowercase. Uppercase works in Python but the YAML parser in dbt expects lowercase.)- Selection ordering. Does
--excluderun before or after--selectin the selection resolution order? (Select first, then exclude from that result.)
And then there is the defer and dbt clone family of questions, which came up several times across my attempts in ways that forced me to get precise. The exam wants you to know:
- What exactly gets deferred when you run with
--defer(unselected upstream refs resolve against the state manifest rather than your dev schema). - When
favor-stateoverrides that behavior. - What
dbt cloneactually copies versus what it creates a pointer to. - How
state:modified+differs fromresult:error+differs fromsource_status:fresher+.
Those are real, useful, production-relevant distinctions. I do not complain about those.
The multiple-acceptable-answers problem
The harder issue, and the one I want dbt Labs to fix, is that some questions have more than one answer that is technically correct in the real world, but only one that matches the exact language the exam writer had in mind. A materialization question might accept both table and 'table' in production, but the exam wants one specific form. A project config question might work with either hyphens or underscores in some spots but not others. A package install command might succeed with dbt deps alone or with dbt deps --upgrade, depending on state.
In those cases you are not really being tested on dbt. You are being tested on whether you can read the exam writer's mind. The right defense is to be extremely literal about the exact words in the prompt: “what does dbt do by default” is a different question from “what can dbt do,” and the exam really does distinguish between them.
I respect the exactness, because configuration typos are real production incidents. If your dbt_project.yml has materialized: 'view' in one place and materialized: view in another, both work. But if your on_schema_changeis typo'd, your incremental model silently drops rows, and nobody notices until the CFO asks why Q3 looks weird. So the exam caring about spelling is not crazy. It just crosses the line occasionally.
That said, some of this would be better tested with complex scenario questions rather than spelling contests. I suspect dbt Labs will iterate here over time, and in the meantime, I will take the W.
Where I go from here
I am not done. Next up on my certification roadmap:
- Databricks Certified Data Engineer Professional
- Databricks Certified Machine Learning Professional
- SnowPro Advanced Data Engineer
All of these are directly connected to the stack MHNG builds for clients. Databricks and Snowflake are the two warehouses I see most often in new engagements, and dbt sits on top of both. Adding the ML Professional on the Databricks side rounds out the story on the AI side of the platform, which matters more every quarter. The goal is to be the person who can walk into a room, understand the entire data platform end to end, and speak the language of every tool in it.
What this certification actually signals
The piece of paper is a proxy. Here is what it proxies for, in practice:
- Trust-layer engineering. Models, tests, and contracts designed so data products can actually be relied on.
- Governance at scale. Model versions, access modifiers, groups, and exposures that let many teams ship on one warehouse without stepping on each other.
- Stateful CI/CD. Slim CI with
state:modified+,defer, anddbt cloneso deploys are fast, safe, and reproducible. - AI-ready data platforms. The modeling, semantic-layer, and documentation rigor that makes text-to-SQL and agentic analytics actually accurate.
If you are standing up dbt and want a certified analytics engineer on it, let's talk
MHNG (Mile High Nomad Group) is a data engineering consultancy. Our transformation layer is dbt. Our extraction layer is Rust with zero data retention. Our delivery model is opinionated, tested, and auditable from day one.
If any of the following sounds like your team right now, I would love to talk:
- “We want to stand up dbt and do not know where to start.”
- “We have dbt, but our tests are failing silently and nobody trusts the output.”
- “We want a semantic layer, but our models are not in shape for one.”
- “Our dbt project grew organically and we now need someone who has actually built this at scale.”
Reach out through the contact form at mhng.tech or find me on LinkedIn.
Closing
dbt is the gold standard for data transformation. That is not marketing, it is the shape of 1 billion downloads and 80,000+ teams. The 2026 State of Analytics Engineering Report makes it very clear: AI is making code cheap, but trust in data is the new constraint. Every organization that wants AI to actually work on top of their data needs someone who knows how to build that trust layer.
That is analytics engineering. That is dbt. And now, formally, that is me.
Onto the next one.
Logan Banks, Founder of MHNG
If you are standing up dbt or need a certified analytics engineer on your team, let's talk.
Contact Us